

Key Takeaways
-
Alibaba Wan 2.6 lets you turn text, images, and audio into 10-15 second cinematic videos with stable motion, true multi-shot storytelling, and synced native sound.
-
Multi-shot videos are traditionally the hardest to pull off because you need coverage, continuity, and editing; Wan 2.6 handles most of that “shot scheduling” and consistency for you, so you get mini-sequences instead of one-off clips.
-
It is ideal for short-form content: ads, explainers, social posts, UGC-style clips, and narrative micro-stories, without needing a traditional editor or color-grading skills.
-
The fastest workflow for most creators is: define your story → gather references (images or a short video) → choose a Wan 2.6 mode (text-to-video or image-to-video) → generate → refine.
Creators want their videos to feel like real films showcasing multiple angles, smooth camera moves, and a clear visual arc. Sadly, few have the budget, time, or team to pull off a traditional shoot.
The catch is that multi‑shot is where video gets hard. You need to plan coverage, match actions across shots, keep characters and lighting consistent, and then stitch everything together in an editor without breaking continuity.
Even with AI in the picture, most AI video models can spit out a flashy clip, but they rarely give you a usable scene you can drop straight into a project. You end up stitching separate generations together, fighting character drift, awkward cuts, and audio that never quite lines up.
The solution? Alibaba Wan 2.6.

Generate videos shots in all the angles with a single prompt using Alibaba Wan 2.6 on invideo
Wan 2.6 is a multimodal AI video model that turns text, images, or both into 10–15 second 720p–1080p videos with native audio, multi‑shot structure, and stable subjects. It is designed as a multi‑shot narrative engine. With Wan 2.6, one prompt can yield wide shots, close‑ups, and transitions that feel like parts of the same moment. Instead of one cool frame, you get compact mini‑sequences with coherent motion and audio‑visual sync that behave more like real scenes.
The real step up however comes when you plug this into invideo. Wan AI on invideo already supports 10‑second, 24fps videos in 1080p with realistic motion, consistent frames, audio sync, and edit‑with‑text controls.
This allows you to chain these Wan 2.6 scenes into full videos, adjust scripts or pacing, and export finished ads or explainers without starting over each time. Together, Wan’s story‑driven clips and invideo’s production workflow turn raw generations into a repeatable way to ship polished, narrative videos at scale.

See how multi-angle shot is used in the video to tell a compelling story
Why Wan 2.6 is a Strong Play for Creators and Marketers
Wan 2.6 by Alibaba was built keeping “multi-shot storytelling” in mind. This means you can describe multiple shots in one prompt so the model schedules and renders a short sequence that feels edited. Wan 2.6 is built for modern, short‑form formats where story, pacing, and consistency matter more than long runtimes. Some of its key benefits include:
-
Multi-shot generation: Wan 2.6 bridges the isolated, disconnected clips issue by breaking a single prompt into several shots, giving you a mini sequence (e.g., wide → medium → close-up) inside one 5–15 second clip.
-
Consistent cinematic quality: Wan 2.6 emphasizes character and scene consistency across shots, reducing flicker and identity drift that usually break immersion in multi-shot AI videos.
-
No crew needed: Wan 2.6 turns text, images, or references directly into finished scene-level videos, so you can bypass cameras, sets, and on-site crews for many marketing, educational, and social content use cases.
For creators, that translates into three big advantages:
-
Narrative structure without editing skills
Multi‑shot generation lets you build a beginning-middle-end inside one 10-15 second output, so you can create social stories, micro‑ads, or mini trailers without stitching clips manually. -
Stable motion and characters
The model focuses on smooth transitions and continuity, which reduces the “glitchy” feel common in older AI video tools and makes outputs more usable straight from the model. -
Audio‑visual alignment out of the box
Native or audio‑driven generation means the model can time cuts and motion to your soundtrack or narration, reducing the amount of post timing you need to fix in an editor.

For marketers and brands, this combination makes Wan 2.6 particularly useful for:
-
Short product demos and promos that need to feel intentional, not random stock footage.
-
UGC-style social videos where pacing and performance sell the story in under 15 seconds.
-
Narrative explainers or micro-stories that need coherent scenes rather than isolated shots.
Comparing Wan 2.6 with Sora 2, Kling 2.6 and Veo 3.1
As you can see, Wan 2.6 is a great fit for creators who care specifically about turning one structured prompt into a coherent multi‑shot, audio‑ready sequence.
How to use Wan 2.6: A Simple 3-step invideo Workflow
Wan 2.6 inside invideo, through its built-in model selector and prompt interface for text‑to‑video and image‑to‑video generation, just so happens to be your very own one-stop solution. All you need is a clear idea of your video and a few reference images or clips to guide Wan 2.6.
Step 1: Plan a 10-15 second mini-story (3–5 shots)
First things first, log in to your invideo account and select ‘Agents and models’ from the main creation dashboard.
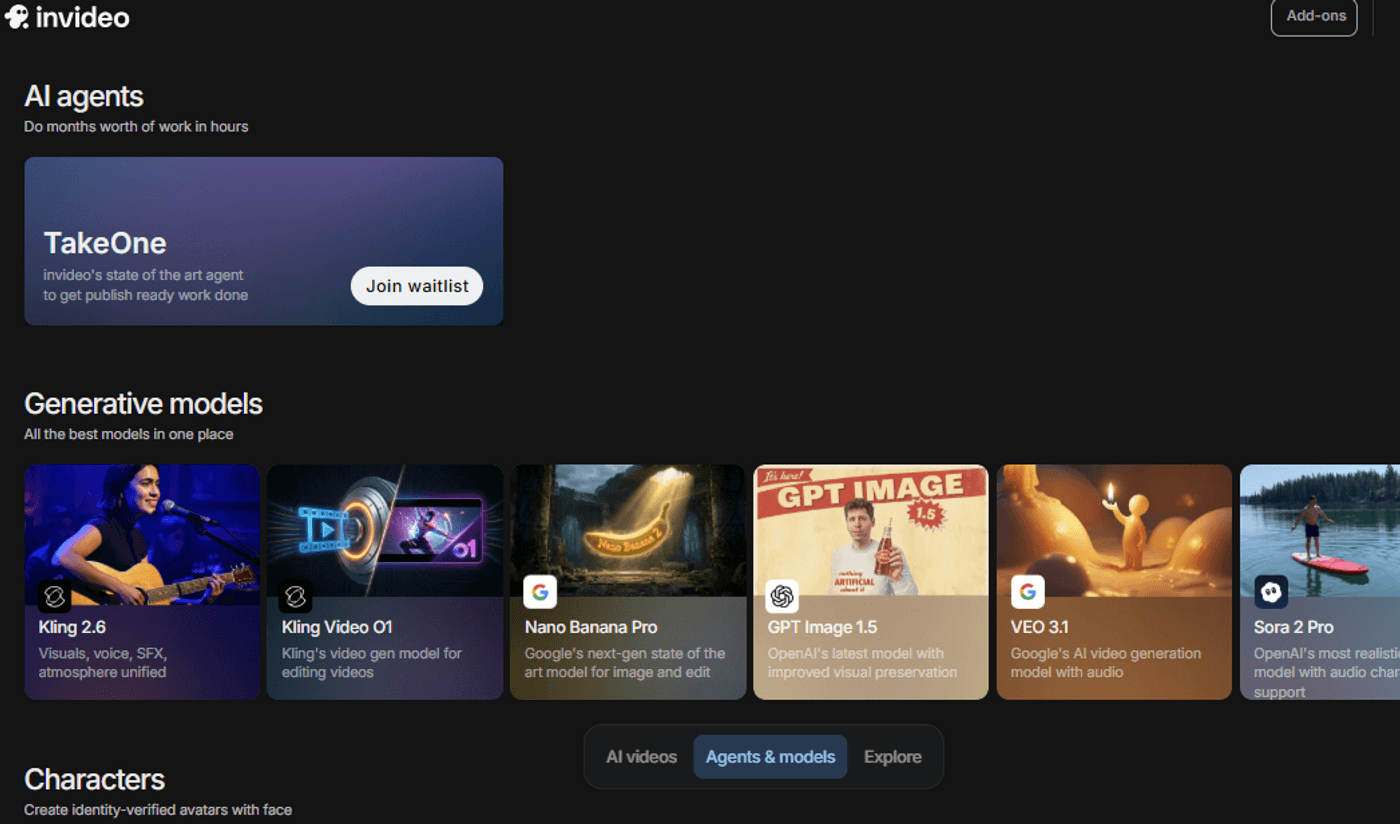
Once there, select ‘Wan 2.6’ and create a new project.
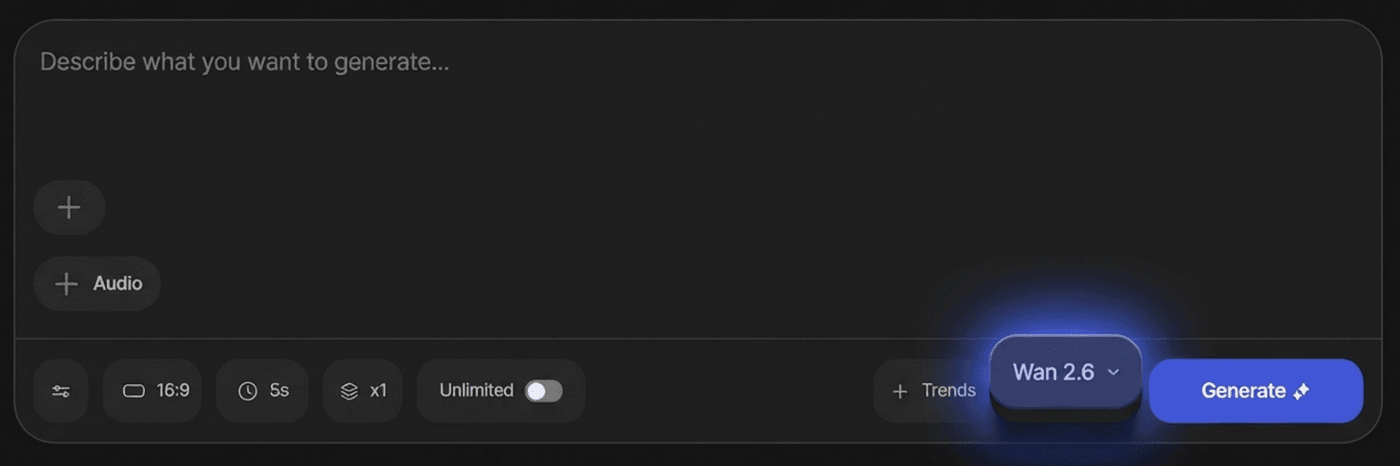
Now that you’re set up, start small and think in multi-shot terms. If you’re aiming for cinematic multi-shot storytelling, 3 shots is enough to feel intentional:
-
Shot 1: establish (where are we, what’s the subject?)
-
Shot 2: move (camera motion + subject action)
-
Shot 3: payoff (close-up reveal, emotional beat, product hero, or twist)
Keep one subject and one location. The moment you change locations mid-sequence, you increase the odds of continuity breaks.
If you’re creating for short-form, decide your aspect ratio early:
-
Use one subject and one location per sequence to minimize drift.
-
9:16 for Reels/TikTok/Shorts (tight framing, strong subject presence)
-
16:9 for YouTube/landing pages (wider establishing shots and lateral camera moves)
Step 2: Choose your mode and set your constraints
Wan 2.6 is commonly used across three modes: text-to-video, image-to-video, and reference-to-video, each with different prompting considerations.
In most creator workflows:
-
Text-to-video is best for “from scratch” cinematic concepts and quick storyboards.
-
Image-to-video is best when you already have a product photo, key visual, or character image and you want motion plus camera language.
-
Reference-to-video is best when you need subject consistency anchored to an existing clip (and you’re willing to be more specific about staging).
Before you click generate however, you should set basic constraints for your multi‑shot run:
Say, for example:
-
Duration: usually 10–15 seconds for 3–5 shots.
-
Resolution: 1080p where available.
-
Motion: pick subtle vs. dramatic camera movement and say it explicitly in your prompt.
A simple starting structure you can paste and edit:
“Cinematic [ASPECT RATIO] video, [SUBJECT] in [LOCATION]. 3 shots over 15 seconds:
Shot 1 [0–4s] wide establishing shot, slow dolly‑in.
Shot 2 [4–10s] medium tracking shot as [SUBJECT ACTION].
Shot 3 [10–15s] close-up of [DETAIL], slow push‑in.
Smooth, stable motion, consistent lighting and wardrobe, native audio that matches the pacing.
Negative: text, watermark, jitter, distorted faces, extra limbs.”
Also decide your non-negotiables up front: duration, resolution, and whether you want subtle or dramatic camera movement. Wan 2.6 guides frequently mention improved quality and speed versus earlier versions, but your settings and constraints still determine whether you get something stable and usable.
Step 3: Generate, review, iterate
After generation, review in this order:
-
Continuity: does the subject stay recognizable? Do wardrobe/props remain consistent? Does the environment feel like the same place?
-
Camera: does it actually push in, orbit, pan, or track the way you intended? If not, slow it down and simplify the move.
-
Artifacts: look for unwanted text, warped hands, flicker, or “rubbery” faces.
Then regenerate with a single change. The biggest mistake creators make is rewriting the whole prompt every time; it’s almost impossible to learn what’s working. Change just one shot description, one camera verb, or one negative prompt line, and see how Wan 2.6 adjusts the multi‑shot sequence.
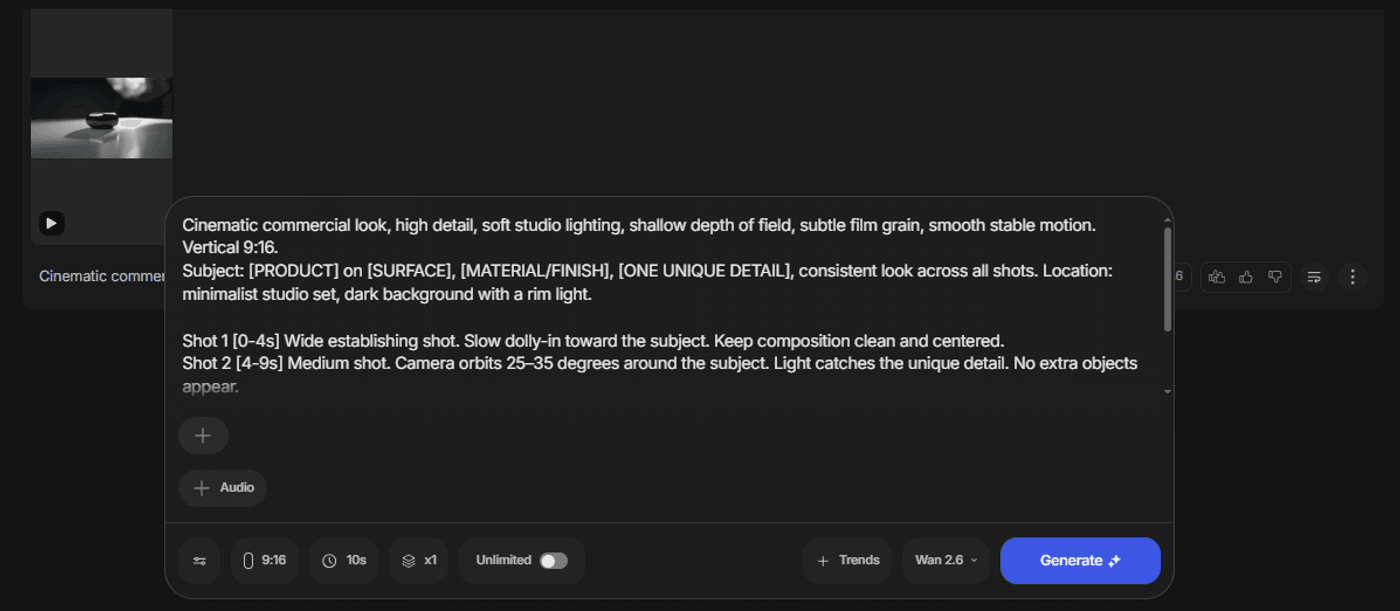
Expert Prompt Templates To Ease Your Workflow
Everything below is designed to be copy-and-paste friendly. Replace bracketed sections and keep the structure.
Template 1: Cinematic product reveal
Use this template when you want Wan 2.6 to behave like a tiny commercial studio for short, vertical spots that have to sell quickly in a feed. The 15‑second, three‑shot structure is ideal for channels where people scroll fast but still expect polished, story‑like movement rather than static product spins.
Cinematic commercial look, high detail, soft studio lighting, shallow depth of field, subtle film grain, smooth stable motion. Vertical 9:16. Subject: [PRODUCT] on [SURFACE], [MATERIAL/FINISH], [ONE UNIQUE DETAIL], consistent look across all shots. Location: minimalist studio set, dark background with a rim light. Shot 1 [0–4s] Wide establishing shot. Slow dolly-in toward the subject. Keep composition clean and centered. Shot 2 [4–9s] Medium shot. Camera orbits 25–35 degrees around the subject. Light catches the unique detail. No extra objects appear. Shot 3 [9–15s] Close-up macro shot of the unique detail. Slow push-in, crisp texture, smooth focus pull. Negative: low quality, blurry, noisy, warped reflections, jittery camera, text, subtitles, watermark, extra hands, deformed shapes
Template 2: UGC-style “founder story” sequence
Use this when Wan 2.6 needs to carry more than a product shot and actually tell a short story about your brand, founder, or mission in a social‑native format. The model’s 5–15 second multi‑shot sequences and native audio make it a good fit for narrative clips that still have to hook fast and feel “thumb‑stopping” in a feed.
Modern UGC ad style, natural indoor lighting, handheld feel but stable, realistic textures, shallow depth of field, warm color grade. Vertical 9:16. Subject: one person wearing [OUTFIT], same hairstyle, same face, in a cozy home workspace with a desk and a laptop. Keep identity consistent. Shot 1 [0–4s] Wide shot. The person sits at the desk, looking focused, slight camera push-in. Shot 2 [4–10s] Medium shot. The person holds [PRODUCT] and gestures naturally, camera drifts slightly left to right. Shot 3 [10–15s] Close-up on hands holding the product, subtle rotation, soft focus background. Negative: cartoon, CGI, distorted face, extra fingers, text overlays, watermark, shaky camera, glitch
If you need actual spoken dialogue, a reliable workflow is to generate visuals first, then add voiceover and captions in post. Invideo can help you handle voiceover, captions, and final timing so the sequence becomes a publish-ready asset without needing perfect on-camera lip sync from the generation step.
Template 3: Trailer-style micro narrative
Use this when you want Wan 2.6 to create short, atmospheric sequences that feel like a movie opener rather than a straightforward product ad. The model’s 15‑second, multi‑shot storytelling with native audio and smooth camera moves makes it well suited for mood‑driven, highly visual pieces that set a tone in just a few beats.
Cinematic trailer, photoreal, dramatic lighting, high contrast, atmospheric haze, smooth camera movement, subtle film grain. 16:9. Main subject: [CHARACTER DESCRIPTION], wardrobe: [WARDROBE], prop: [PROP]. Location: [ONE LOCATION], time: [TIME OF DAY]. Keep continuity across all shots. Shot 1 [0–3s] Wide establishing shot of the location. Slow crane down revealing the subject in frame. Shot 2 [3–6s] Medium tracking shot following the subject walking forward. Wind moves clothing subtly. Shot 3 [6–9s] Close-up on the subject’s face, controlled expression, shallow depth of field, slow push-in. Shot 4 [9–12s] Over-the-shoulder shot revealing [REVEAL ELEMENT], slight handheld feel but stable. Shot 5 [12–15s] Wide shot. The subject stands still as lighting shifts subtly, cinematic end frame. Negative: low quality, blurry, text, watermark, distorted face, deformed hands, flicker, unnatural movement
Template 4: Image-to-video “camera language” prompt
If you’re using image-to-video, the most effective prompts usually focus on what changes over time: camera, lighting, atmosphere. Many guides recommend not over-describing what’s already in the image and instead describing the motion and temporal changes.
Continue from the first frame. Subtle camera push-in and slight orbit to the right. Gentle parallax, soft lighting shift from neutral to warm, cinematic and smooth motion. Add faint floating dust particles in the air. No new objects added. Negative: jitter, warping, text, watermark, low quality, flicker
Here’s a sample Wan 2.6 video created on invideo using one of the prompt examples shown above.
Best Practices For Coherence
-
Repeat your subject description in every shot line because consistency is more about stable anchors than extra adjectives. If the model “forgets” who the character is in shot 2, it’s usually because the prompt stopped describing them clearly.
-
Keep camera movement smooth and singular per shot because “cinematic” usually reads as controlled motion, not maximum motion. A slow push-in or orbit often looks more expensive than a fast whip pan.
-
Use a simple continuity trio: wardrobe, prop, location, and include those words in every shot. This creates “sequence video generation” that feels connected rather than three unrelated clips.
-
Limit yourself to 3–5 shots until you get reliable results because longer shot lists increase the chance of drift. Once you have a stable prompt style, you can expand.
-
Treat negative prompts as mandatory guardrails rather than optional polish because they reduce common failures like text overlays, warped faces, and flicker.
Directing WAN 2.6 Like a Sequence Engine, the invideo Way
Wan 2.6 is most powerful when you treat it like a sequence engine: plan a tiny storyboard, prompt in shots with timing brackets, and iterate like a director. That combination is what unlocks multi-shot video generation that feels coherent and cinematic, even if you’re creating without a crew.
Wan AI on invideo turns Wan 2.6 from a powerful model into a full multi-shot video production pipeline: you generate 1080p, 24fps, audio-synced clips, then refine everything, script, visuals, timing, and sound, without ever leaving the browser. Instead of juggling separate tools for generation, editing, and formatting, you get one workspace that keeps motion quality, character consistency, and prompt accuracy intact while you polish the final cut.
So what are you waiting for? Try Wan 2.6 free for 7 days
FAQs
1. What is Alibaba Wan 2.6 in simple terms?
Wan 2.6 is an AI video model that turns prompts, images, and audio into short, cinematic videos with multiple shots, smooth motion, and native sound, optimized for 10–15 second clips.
2. Do I need editing experience to use Wan 2.6?
No. If you can describe a scene in plain language and upload a few images, you can generate usable short‑form videos; light editing afterward (captions, logos) is helpful but not mandatory.
3. What kinds of videos is Wan 2.6 best for?
It is strongest at short narratives, ads, product teasers, UGC‑style clips, and explainers where you need coherent scenes, stable motion, and decent audio in a 10–15 second package.
4. How long can Wan 2.6 videos be?
Most implementations cap at around 10–15 seconds per generation, which is ideal for social posts, hooks, and micro‑stories but not for long‑form YouTube content.
5. Can I use Wan 2.6 for client or commercial work?
In many cases yes, but licensing and usage terms depend on the platform or API provider you use; always confirm their commercial policy before using outputs in paid campaigns.
6. What are the best prompts for consistent character identity?
Use Wan 2.6 on invideo with multi‑shot prompts that repeat the same character description (age, wardrobe, hairstyle, props) in every shot line. This gives the model strong anchors to keep the character consistent across all shots.
7. How Wan 2.6 used to script multiscene video workflows?
In a multi‑scene workflow, you treat Wan 2.6 as a shot‑scheduler: you write a prompt that explicitly breaks the sequence into timed shots (e.g., “Shot 1 [0–4s] wide… Shot 2 [4–10s] medium…”), then generate 10–15 second sequences that already contain several angles. You then chain these sequences on invideo’s timeline to build longer stories.
8. Do multiscene videos ensure character consistency?
Yes. Wan 2.6 on invideo is tuned to keep characters stable within each multi‑shot sequence when you repeat key descriptors per shot and stick to one subject and location.
9. What is the difference between Wan 2.6, Sora 2, Kling 2.6 and Veo 3.1?
Wan 2.6, Sora 2, Kling 2.6, and Veo 3.1 are all strong AI video models, but they lean in different directions. Wan 2.6 is optimized for short, multi‑shot sequences with native audio, Sora 2 for longer continuous cinematic scenes, Kling 2.6 for fast, kinetic, social‑native motion, and Veo 3.1 for high‑end, filmic realism and hero shots.