ChatGPT Images 2.0 (the model is called GPT Image 2) is OpenAI's newest image model and represents a real leap, not a spec bump. It finally renders text you can read. It works in languages that were off-limits before. It plans a layout before it draws. But it is not magic, and it has some shortcomings.
So let’s break down what GPT Image 2 can actually do, where it still falls short, and how you can use it in your creative workflow.
Quick Rundown
-
OpenAI rebuilt ChatGPT Images 2.0 from scratch and is retiring DALL-E. This is now their only image model.
-
GPT image 2.0 uses disruptive tech. It generates images like LLMs generate text vs the diffusion process used by all prior models.
-
The biggest leap is text rendering: 99% accuracy in English, and over 90% in Chinese, Japanese, Korean, Hindi, Bengali, and Arabic.
-
It is the first image model with built-in reasoning, meaning it can plan layouts, pull information from the web, and verify its own output before delivering.
-
Aspect ratios now range from 3:1 to 1:3 with native 16:9 and 9:16 support, and standard output sits at 2K resolution, with 4k support through the API in beta.
-
This article covers the architecture shift behind it, the five features that matter most, where it still falls short, how it compares to Midjourney, FLUX, and Nano Banana 2, and how to use it inside a larger workflow with invideo.
What is ChatGPT Images 2.0 or GPT Image 2?
What sets GPT image 2 apart from earlier generations isn't just sharper output; it's a shift in how the model works.
Rather than translating a prompt directly into pixels, it behaves more like a creative collaborator that interprets intent, plans the composition, and refines results.
It's available both inside ChatGPT and through the OpenAI API, and is positioned less as a novelty image tool and more as a production-grade asset generator for real design and content workflows.
What can you actually do with ChatGPT Images 2.0?
The features only matter if they change your workflow. Here is where ChatGPT Images 2.0 earns its place in a brand's creative stack.
1. Accurate text adherence in ad creatives
This is the big one. Ninety-nine percent text accuracy means the headline, the subhead, and the CTA come out readable in a single pass.
No exporting to Photoshop to fix a misspelled word. No designer round-trip for a one-line change.
A DTC brand can generate ten ad variations, each with different copy, and ship the ones that work. The two-step "generate, then fix the text" workflow is gone.

2. Product packaging and label mockups
Brand copy on a label used to be where AI fell apart. Now it holds.
Generate a notebook with the actual product name and tagline spelled correctly. Test three label directions before a single physical sample is printed.
Plus you can run the same campaign in Mandarin, Hindi, Japanese, Korean, and Arabic without a separate localization pass for each. The text renders correctly in scripts that were completely off-limits before.
A global brand can launch in six markets with on-brand visuals, not placeholder English.

It is a faster, cheaper first draft for the packaging team.
3. Social assets in every format from one idea
Aspect ratios now run from 3:1 to 1:3, with native 16:9 and 9:16.
That means one prompt becomes a YouTube thumbnail, an Instagram Story, and a wide LinkedIn banner. No cropping. No reframing.
A social team can fill a week of content in formats that actually fit each platform.

YouTube thumbnail |

Instagram cover |

Carousel slides |
4. Infographics
Dense layouts hold together now. Multiple data points, labels, and headers stay where you put them.
A B2B brand can turn a stat-heavy report into a clean, on-brand infographic without handing it to a designer first.
5. Consistent characters, environments and illustrations
You can use GPT Image 2 to design unique game characters, create memorable brand mascots, develop fictional personalities, or generate concept art for creative projects, instead of relying solely on written descriptions.
Beyond characters, the model is also useful for environment design. Creators can generate fantasy worlds, futuristic sci-fi cities, historical settings, or immersive virtual locations that help establish the tone and atmosphere of a project.


For storytellers, ChatGPT Images 2.0 makes it easier to visualize scenes and moments from a narrative. Writers, comic creators, and publishers can create illustrations for key story beats, experiment with visual storytelling, and explore how characters and environments work together within a scene.


6. UI and concept mockups
Instruction-following is strong enough that UI mockups come out clean.
A product team can describe a screen and get a mockup ready to hand to a coding tool, or to a stakeholder for sign-off.
7. Editorial covers and layouts (Magazines & books)
For magazine covers, creators can experiment with different concepts, styles, and compositions to produce eye-catching visuals that stand out on both digital and print platforms.
Whether it's a technology feature, fashion issue, business publication, or cultural magazine, AI-generated imagery can help bring cover stories to life in unique ways.
The model is also useful for creating editorial illustrations and supporting visuals throughout a publication. Designers can generate custom artwork for feature articles, opinion pieces, interviews, and special reports, ensuring a consistent visual style across every page.



Where ChatGPT Images 2.0 still falls short?
It’s the most capable image model right now, but not perfect. Keep these in mind before depending on it for production:
-
Restart your session between batches. The model can carry over data within a session and noise can build up, degrading quality.
-
Generating many posters can converge on one style; vary prompts with explicit style directions.
-
It still struggles with physics, structural accuracy, technical data, close-up faces, and text on curved or steeply angled surfaces. Treat it as a strong starting point that still needs human review.

5 ChatGPT Images 2.0 features that make it one of the top AI image generation models today
1. It reasons before it generates
GPT Image 2 is the first image model that thinks before it draws, using the same O-series reasoning behind OpenAI’s text models. Before a single pixel, it can analyze the prompt, plan layout and spatial relationships, pull information from the web, and reason through compositional constraints, then verify its own output.
2. 99% text-rendering accuracy
This is the headline. GPT Image 1.5 scored roughly 90–95% on text, meaning one in ten words could be wrong, almost guaranteeing an error on any poster.
GPT Image 2 pushes that to a claimed 99% for both Latin and CJK scripts, so most single-pass outputs come back clean.
Full pages of readable text, magazine covers, product labels, scientific diagrams, and menus where every dish is a real word. It treats typography as a design element, not text floating on top.
3. Multilingual text (CJK, Hindi, Bengali, Arabic)
Previous models could barely spell English; non-Latin scripts were out of the question. GPT Image 2 renders Chinese, Japanese (Kanji and Hiragana), Korean, Hindi, Bengali, and Arabic writing systems with thousands of characters and complex rules.
That opens product packaging in Mandarin, campaigns in Hindi, UI mockups in Japanese, and K-pop assets in Korean, all without a manual correction pass.
4. Resolution, aspect ratios, and color
Standard output is 2K (2048px); 4K is in API beta (anything above 2560×1440 flagged experimental).
The bigger quality-of-life win is aspect ratios: where 1.5 gave you 1:1, 3:2 and 2:3, GPT Image 2 supports 3:1 (ultra-wide) to 1:3 (tall vertical), including native 16:9 and 9:16, so no more cropping every thumbnail and Story. The warm yellow color cast from 1.5 is also gone.
5. Stronger instruction-following and composition control
Spatial instructions work (“three identical robots in a row,” “the red mug to the left of the laptop”). Multi-edit prompts hold up, change a sign, swap a label, adjust a background in one request.
You can manipulate objects by name (“remove the person in the blue jacket”) with no masking. And dense compositions, infographics, multi-panel comics, magazine spreads hold together because the model handles layout logic, not just visual quality.
ChatGPT Images 2.0 vs Midjourney, Nano Banana 2 and FLUX
Every model has a lane. Here’s where each one leads.
To experiment, we ran a simple prompt through all four models and the results are in front of you.
Prompt: "Create a premium YouTube thumbnail in a modern AI-tech editorial style. Split the composition into two contrasting halves. On the left side, showcase stunning AI-generated visuals emerging from a glowing ChatGPT-inspired interface: cinematic portraits, realistic product photography, vibrant illustrations, and professional marketing creatives. Use bright lighting, vibrant colors, futuristic UI elements, and upward arrows to symbolize benefits and innovation. On the right side, depict the limitations and challenges of AI image generation: distorted hands, inconsistent text rendering, failed generations, quality issues, and warning symbols. Use darker tones, subtle glitch effects, red highlights, and broken image frames to create contrast. In the center, feature a large glowing AI image-generation panel with an image transforming from rough concept to polished masterpiece. Add dynamic particles, depth, dramatic lighting, and premium tech aesthetics. Large bold headline text: Here's EVERYTHING YOU NEED TO KNOW ABOUT CHATGPT IMAGES 2.0 Secondary text: BENEFITS vs FALLBACKS Typography should be huge, bold, modern sans-serif, highly readable at mobile size. Use white text with subtle shadows and cyan accents. Maintain strong visual hierarchy similar to top-performing AI and technology YouTube thumbnails. Ultra-sharp, high contrast, professional, viral-worthy, clean composition, 16:9 aspect ratio."

ChatGPT Image 2.0

Nano Banana 2

Midjourney v8

Flux
How to access and use ChatGPT Images 2.0?
There are two practical ways to use GPT Image 2:
In ChatGPT
Base image generation is available to all ChatGPT users. Selecting a thinking or pro model unlocks the reasoning layer: real-time web search during generation, up to ten images at once, and character/object continuity across them.
In invideo (with your context kept)
Autopilot
-
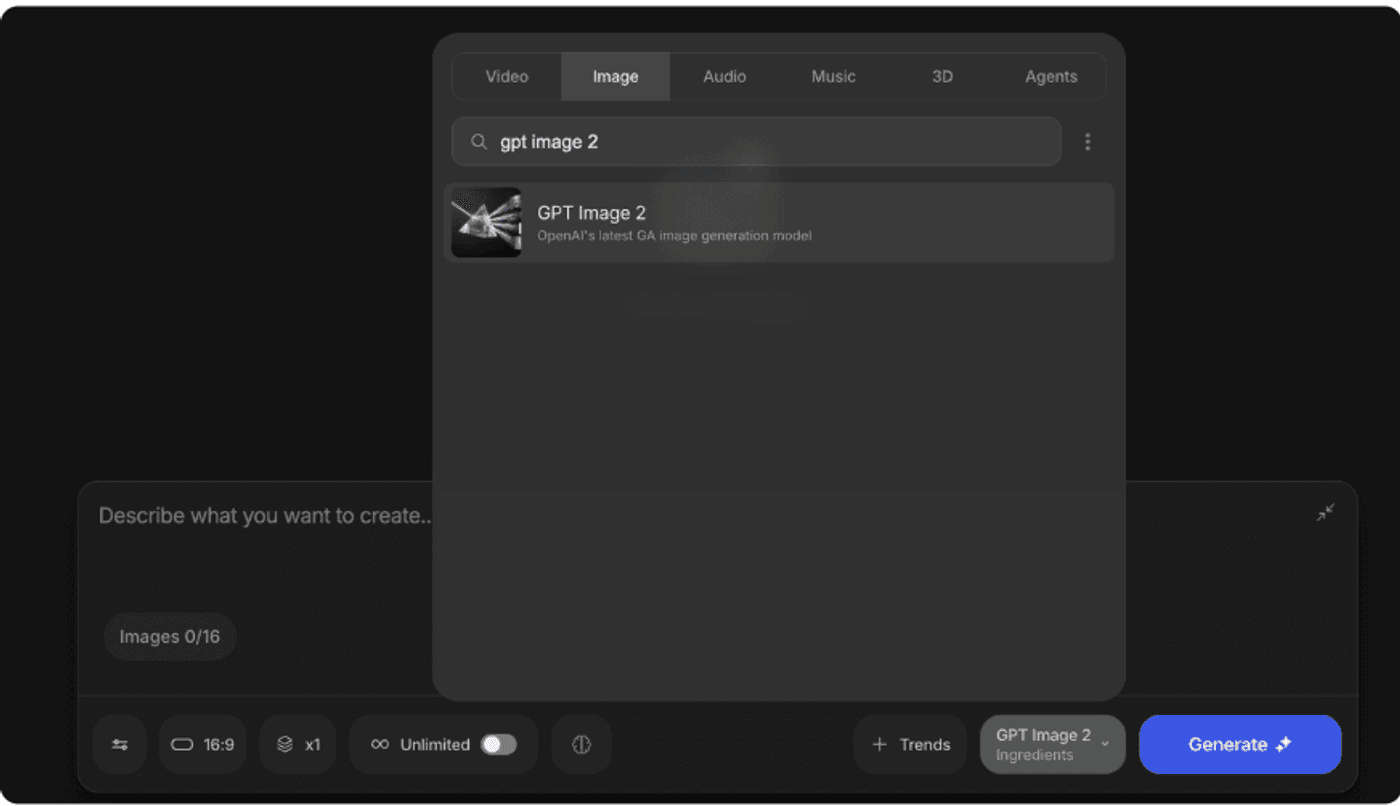
Step 1: Open Agents & Models, select GPT Image 2 under image models.
-
Step 2: Write your prompt, set resolution and number of variations, and generate.
Agent One
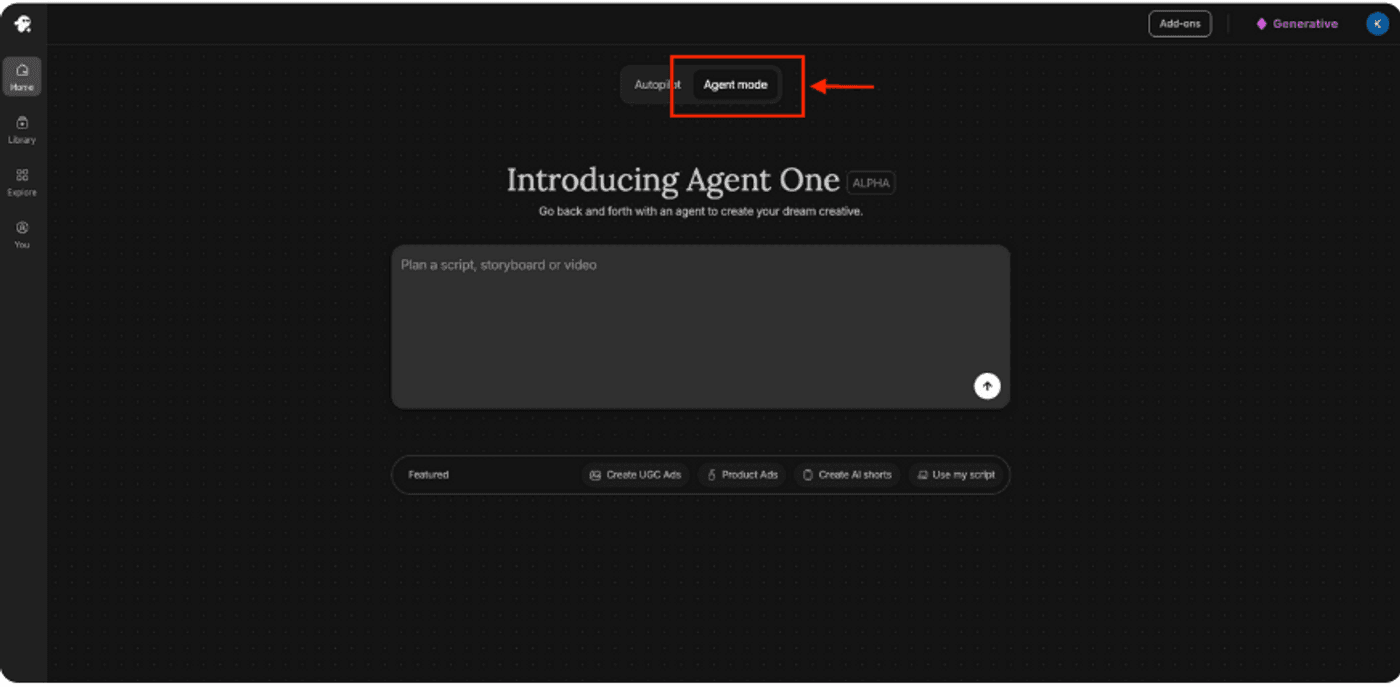
This requires just one step.
Tell Agent One what you need in plain language, and have it use GPT Image 2 to ideate, write the prompt, and produce variations in one pass.
The difference from using GPT Image 2 in raw ChatGPT is that invideo holds your context, your brand, style, and scene. So iteration is a conversation instead of a cold start, and the image goes straight into your video or campaign without exporting.
FAQs
-
1.
What is ChatGPT Images 2.0?
ChatGPT Images 2.0 (model name GPT Image 2) is OpenAI’s newest image-generation model, released April 21, 2026. It replaces the older GPT image pipeline and becomes OpenAI’s main image model after DALL·E 2 and 3 are retired on May 12, 2026.
-
2.
How do I use ChatGPT Images 2.0?
You can use it inside ChatGPT, or in invideo: open Agents & Models, select GPT Image 2, write a prompt, set resolution and variations, and generate. In invideo your brand and scene context carry across generations.
-
3.
What’s the biggest improvement in GPT Image 2.0 over GPT Image 1.5?
Text rendering. Accuracy moved from roughly 90–95% to a claimed 99%, which makes single-pass posters, ads, packaging, menus, and UI mockups usable without an editing step.
-
4.
Does ChatGPT Images 2.0 support different aspect ratios?
Yes, from 3:1 (ultra-wide) to 1:3 (tall vertical), including native 16:9 and 9:16, plus square. Standard output is 2K, with 4K in API beta.
-
5.
Can GPT Image 2.0 generate text in other languages?
Yes. It renders Chinese, Japanese (Kanji and Hiragana), Korean, Hindi, Bengali, and Arabic, opening markets that earlier models couldn’t serve.
-
6.
Where does ChatGPT Images 2.0 still fall short?
Physics, structural accuracy, technical data, close-up faces, and text on curved or steeply angled surfaces. It’s a strong start but production work still needs review.
-
7.
Is ChatGPT Images 2.0 better than Midjourney?
It depends on the job. GPT Image 2 leads on text accuracy, layout-heavy assets, multilingual rendering and instruction-following; Midjourney may still lead on pure visual style.
-
8.
Is GPT Image 2.0 a major update or just a minor one?
It's a major one. ChatGPT Images 2.0 (GPT Image 2) is OpenAI's third image model in thirteen months, and OpenAI rebuilt the architecture from scratch, it no longer runs on the GPT-4o image pipeline that powered earlier versions. OpenAI is also retiring DALL·E 2 and DALL·E 3 on May 12, 2026, making GPT Image 2 its only image model going forward.
-
9.
How does GPT Image 2.0 get text accurately right and other AI image generation models can't?
Every major generator before this DALL·E 3, Midjourney, Stable Diffusion ran on diffusion. Hence, these models learned what text looks like, not what it means. GPT Image 2 is autoregressive: it generates images the way a language model generates text, one token at a time, processing pixels and text through the same pipeline. When it writes a headline, it constructs the letters as language, not as shapes that resemble letters. That’s why text accuracy jumped from 90–95% to 99%.