Quick Rundown
-
The market is calling HappyHorse 1.0 the new Seedance 2.0 killer. So we tested it. Four prompts, both models, four generations each, best one picked.
-
Seedance won every prompt.
-
HappyHorse 1.0 is impressive engineering with a genuinely new architecture underneath it. It's also, in our testing, not the model the launch story said it was. The AI leaderboard has already moved, Seedance 2.0 is back at #1, and the gap between the two is wider than the rankings make it look.
-
This is the piece that walks you through what we saw.
What is HappyHorse 1.0?
Built by Alibaba's Taotian Future Life Lab, with Zhang Di leading the project. Zhang designed Kling 1.0 and Kling 2.0 at Kuaishou before rejoining Alibaba in late 2025.
HappyHorse is his first output at the new lab. The architecture is the part of the story worth understanding.
Most video models, Seedance included, build the video first, then add the audio. Two separate processes that are stitched together at the end. HappyHorse builds them at the same time, in the same step.
The voice and the lip movement come out of the model together, not glued on after. Anyone who's sat through bad lip-sync in an AI video knows exactly why this matters.
The rest of the specs are good on paper:
-
15 billion parameters
-
1080p output
-
Up to 15 seconds per clip
-
Native lip-sync in six languages
-
It takes around 38 seconds to generate a 1080p clip on a single H100, which is three to six times faster than most competing diffusion models
Read that list and the "Seedance killer" headline almost writes itself.
Why Did HappyHorse 1.0 Come Into The Limelight?
On April 7th, 2026, a model called "HappyHorse-1.0" appeared at #1 on the Artificial Analysis Video Arena leaderboard. No team. No paper. No website that pointed anywhere real.
Arena flagged it as "pseudonymous." For two days, nobody knew who built it. Then Alibaba claimed it.
This is now a Chinese AI playbook:
DeepSeek did it.
Xiaomi did it with MiMo-V2.
Drop the model anonymously, let the blind-vote benchmark do the marketing, claim ownership only after #1 is locked.
The trick works in their favor because the numbers feel more credible when nobody knows the brand. Voters picking between two clips can't tell they're choosing Alibaba over ByteDance.
By the time the reveal landed, the launch narrative had already set. Seedance 2.0 killer. Frontier model. New SOTA.
A few weeks have now passed. The hype has had time to cool. It’s at #2 on the Arena.AI leaderboard with Seedance 2.0 at the top.
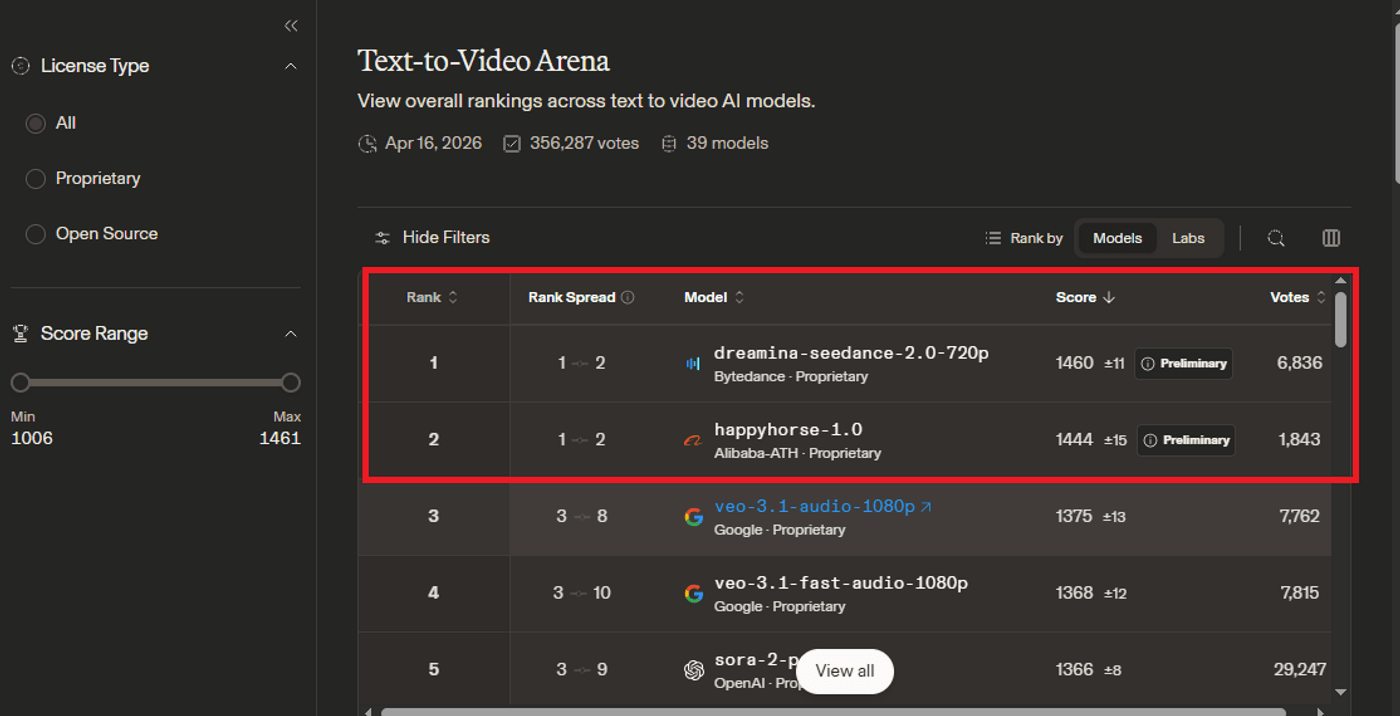
So the question worth asking now isn't "what is HappyHorse." Every blog already answered that.
The question is whether the outputs ever backed up the launch story.
So we tested it.
Head-to-head: HappyHorse 1.0 and Seedance 2.0 Compared
Four prompts for both models.
We ran four generations per prompt and picked the best one from each. What you're about to see isn't either model's average. It's each model's best foot forward.
The prompts test what AI video models in 2026 still struggle with: dialogue with two faces, multi-shot character continuity, action choreography with weight, and image-to-video with sustained physical action.
Prompt 1: Two characters in conversation
Two friends sit across from each other at a small wooden cafe table by a rain-streaked window. The woman, mid-thirties, dark hair pulled back, leans forward and says: "I told him exactly what you said." The man, slightly younger, beard, looks up from his coffee, raises an eyebrow, and replies: "And what did he do?" She sits back, half-smiles, says: "Nothing. He just stared at the floor." Medium two-shot, slight rack focus between them as each speaks. Warm interior lighting, soft rain visible through the window behind them, faint cafe ambience and rain sounds. Naturalistic indie film aesthetic.
This is the hardest possible test for a model claiming joint audio-video generation. Two faces. Three lines of dialogue. Reactions between them. If HappyHorse's architecture is the breakthrough the launch said it was, this is where it should pull ahead.
HappyHorse 1.0:
-
Lip-sync is clean
-
Audio is clean
-
The expressions do not match the lines
-
The faces are oversharpened and have an AI-look to them
-
The video reads as AI in the first second
Seedance 2.0:
-
Different scene entirely, natural expressions and acting
-
Film-like camera quality
-
Lip-sync and audio are clean
-
This one reads more like a scene and not a render
The architecture did its job. The performance didn't manage to land.
Winner: Seedance 2.0
Prompt 2: Multi-shot with character continuity
Shot 1: A man in his thirties, short dark hair, wearing a faded green canvas jacket, walks alone down a narrow cobblestone street at golden hour. Long shadows, warm light on the buildings. Medium tracking shot from the side, moving with him. He glances at his watch, picks up his pace. Shot 2: Same man, same jacket, same hair, now stepping into the warm light of a small bookshop interior. Wooden shelves, dim amber lamps, a few customers browsing in the background. He looks around, spots something off-screen, and walks toward it. Medium shot from inside the shop, slight handheld feel. Cinematic indie film aesthetic throughout. Warm golden tones in shot 1, warmer amber tones in shot 2. Faint street ambience in shot 1 transitioning to quiet bookshop ambience in shot 2.
Multi-shot is where models that handle single clips fall apart. The character has to hold across the cut. The wardrobe has to hold. The lighting has to shift between exterior and interior without breaking continuity.
HappyHorse 1.0:
This is the one HappyHorse mostly got right. This is watchable as a clip, but still not entirely usable:
-
Cinematic feel with smooth camera movements
-
Character and wardrobe hold across the cut
-
Multi-shot sequence holds and has a coherent cut
-
But the lighting logic breaks. The sun is behind, the face is lit from the front
-
The library signage and the woman flipping pages in the background are rendered incorrectly
-
Cinematic handheld camera feel
-
Natural lighting that is consistent across cuts
-
No broken background detail
-
Usable as is, can go straight into a project
The closest HappyHorse 1.0 comes to a clean win. But ‘closest’ still isn't close enough.
Winner: Seedance 2.0
Prompt 3: Action-sequence
[CHARACTERS] Ronin: middle-aged Japanese male, scar over right eye, brown tactical jacket, black ballistic vest, katana. Character sheet attached — do not alter. Assassin: grey tactical suit, hood up, face in shadow. Only these two characters in frame at all times. [LOCATION] One brutalist indoor courtyard throughout. Glass window already shattered before Shot 1. Broken glass and pooling rain on concrete floor throughout. No sky. No exterior shots. [LIGHTING — DO NOT CHANGE BETWEEN SHOTS] Single amber street lamp, frame right, 45 degrees above. Amber rim right, cobalt-blue shadow left on all surfaces and characters. No other light sources. No text or signage in frame. [RAIN] Hyper-realistic rain simulation on skin throughout. Droplets break apart on Ronin's face, stream down his scar, soak hair flat, bead on eyelashes. Jacket darkens progressively each shot. [SHOT 1 — 00–03s] Visual: Mid-action, no setup. Low angle, close. Action: Ronin and Assassin clash blades mid-strike. Heavy impact — sparks burst and fall into puddles. Feet shift on wet concrete, water splashing. Glass crunches underfoot. Camera: Tight lateral tracking, right-to-left. No cuts. [SHOT 2 — 03–06s] Visual: Continuation. Action: Ronin presses forward with 2 aggressive strikes. Assassin deflects cleanly. On third strike, Assassin redirects and lands a sharp body hit. [SHOT 3 — 06–09s] Visual: Close-range struggle. Action: Ronin stumbles → recovers instantly. Steps inside distance. Blades scrape, forearms collide. They fight in tight proximity. [SHOT 4 — 09–12s] Visual: Critical shift. Action: Simultaneous strike → blades collide and LOCK. They push in — faces close. Then: Ronin subtly changes grip and angle (important detail) He slides his blade along the Assassin's, forcing it off-line. → creates a small opening. [SHOT 5 — 12–15s] Visual: Finish — fast, controlled, grounded. Action: From the opening: Ronin steps in traps the Assassin's weapon arm delivers a clean, decisive close-range strike (torso-level, no exaggerated motion) Assassin freezes — then collapses out of frame. Aftermath Beat (IMPORTANT): Ronin holds position for a beat breath heavy rain pouring blade still No celebration. Just stillness. Camera: Slight push-in during finish → then locked-off for final beat. [PHYSICS + STYLE] Blade resistance on all impacts No exaggerated finishing move Strike must feel efficient and final Body collapse obeys gravity (no float) Water reacts to final movement No clipping, no randomness 24fps photorealistic Lighting unchanged.
This is the most demanding prompt in the set. Timed shots. Locked lighting. Two characters who have to hold across all of them. Choreography that has to feel weighted, not pantomimed.
HappyHorse 1.0:
This clip is unusable.
-
The blades pass through air without weight
-
The two fighters move like they're going through a routine they haven't rehearsed
-
Bad lighting and a lack of the locked amber-and-cobalt color separation the prompt called for
-
The closest description is that they look like they're dancing, badly
Seedance 2.0:
This clip has the widest gap between the models out of all four prompts.
-
True cinematic feel
-
Intentful lighting, real weight on the blades, the amber rim and cobalt shadow that the prompt asked for actually showing up on both characters
-
The choreography has tempo and intention
-
Impacts still aren't perfect, but the difference is night and day
Clear winner: Seedance 2.0
Prompt 4: Noodle Dough Physics Test (image-to-video)
The chef begins pulling the dough outward with both hands in a smooth, practiced motion, stretching it into long noodle strands. He folds the stretched dough once and pulls again, separating it into thinner strands as loose flour shifts across the counter. His face stays focused and calm throughout. The camera holds steady on the counter while keeping both the chef's hands and face visible. Lighting remains consistent with the source image. Faint kitchen ambience, soft rustling of dough and flour, and subtle movement on the wooden surface.
The I2V stress test. The character has to hold identity while their hands do something physically specific. The dough has to behave like dough. The lighting from the source image has to carry through. Hand-and-object interaction is still one of the hardest things in AI video.
HappyHorse 1.0:
The audio actually works and the kitchen ambience is right. That’s one good element. But here are the other details:
-
Opens in unwanted slow motion
-
Dough morphs while folding
-
Warping Apron text
-
Unnatural expression
Seedance 2.0:
Again, the difference is very apparent.
-
The dough behaves like dough, the physics holds
-
The expressions are natural
-
The apron text stays accurate to the source image
-
The audio is on point and the pacing is right
The clip is usable.
Winner: Seedance 2.0
Summary of Our Observations
Seedance won every prompt.
The multi-shot was the only one HappyHorse came close on, and even there a working creator wouldn't ship it.
The pattern across all four was consistent. HappyHorse handled the technical layers. Lip-sync, audio, basic identity. It failed at the layer above that, where output becomes footage someone wants to watch. Performance, lighting logic, weight, rhythm.
The conversation prompt was the most telling. That was the prompt the architecture was supposed to win.
So Is It Really a Seedance 2.0 Killer? Our Early Verdict
Not yet.
The architecture is novel. The 8-step inference & audio-video sync is structurally different from how every other model in the top tier does it.
HappyHorse 1.0 is a first version from a serious lab with some serious engineering prowess.
But "Seedance 2.0 killer" was a claim about the outputs. The outputs aren't there.
Seedance 2.0 is also multimodal. It takes up to 12 reference assets per generation:
-
Nine images
-
Three video clips
-
Three audio files
-
All with the @-tag. It gives full control over which input shapes which part of the output
This is SOTA material.
This could have been the story the launch said it was.
It isn't yet. Maybe the next version. Alibaba is the same outfit that shipped Wan 2.2 with full open-source weights and an Apache 2.0 license, and Zhang Di's track record speaks for itself.
The next version of HappyHorse is the one to watch.
For now, if you're choosing a model for your next project, Seedance 2.0 is still the answer. HappyHorse arrived at #1 by doing something genuinely new. That's worth the respect. It just isn't, yet, worth replacing Seedance over.
Frequently Asked Questions
-
1.
Is HappyHorse 1.0 open source?
The release was announced as open source, but as of late April 2026, no model weights, inference code, or license file have been published. The model is currently accessible only through API providers like Alibaba's Dashscope and partner platforms. Until weights and a license ship, it's open access, not open source.
-
2.
Should I use HappyHorse 1.0 or Seedance 2.0 for my project?
For most creator workflows in 2026, Seedance 2.0 is still the model to beat. If your project depends on synchronized audio-video in narrow single-shot scenes, particularly multilingual lip-sync work, HappyHorse 1.0 is worth testing for that specific case. For multi-shot work, reference-driven workflows, or anything that benefits from precise control over multiple inputs, Seedance is the clear choice.
-
3.
Where can I use HappyHorse 1.0?
HappyHorse 1.0 is available on invideo, alongside Seedance 2.0 and the rest of the top-tier video models. You can run all the prompts in this piece on either model from a single workspace and decide for yourself.
-
4.
How does HappyHorse 1.0 generate audio and video together?
HappyHorse uses a unified Transformer architecture that processes text, image, video, and audio tokens in a single forward pass through one shared sequence. Most other video models, including Seedance 2.0, generate the video first and add the audio second through a separate process. HappyHorse's approach means the voice and the lip movement come out of the model in the same step.