Most people who try Seedance 2.0 for the first time make the same mistake: they treat it like a text-only video model.
They write one dense paragraph stuffed with style words, dramatic adjectives, and camera terms, then expect the model to figure out the timing, pacing, movement, and visual consistency on its own.
Sometimes that works. More often, it doesn't.
This Seedance 2.0 prompting guide fixes that. Seedance 2.0 is a multimodal AI video generation model. It reads text, images, video references, and audio in the same prompt window, and it rewards clear direction over clever wording.
Below you'll find the core prompt formula, the prompt types Seedance 2.0 accepts, five high-impact tips, and a library of ready-to-use prompts with output placeholders you can copy, paste, and adapt.
Key takeaways
-
Seedance 2.0 works best when you split control across text, images, video references, and audio, rather than cramming everything into one paragraph.
-
The simplest way to prompt it: use text to build the environment and a reference video to capture motion.
-
In a strong Seedance 2.0 prompt, text defines the world, images lock identity, video guides movement, and audio shapes rhythm and sound.
-
The mistakes to avoid: too many style adjectives, unclear reference roles, and low-quality source clips.
-
For more consistent Seedance 2.0 AI video generation, start with short tests and keep your references clean.
What is the basic prompt formula for Seedance 2.0?
You don't need a complicated formula to write a good Seedance 2.0 prompt, but you do need structure.
The single most important thing to understand is how the model reads a prompt: the first 20–30 words carry the most weight.
Seedance 2.0 uses the opening of your prompt to lock in the subject and the core action before it processes the rest.
So the practical rule is simple: lead with who or what is in the frame, then what they're doing. Save style, lighting, and atmosphere for after the subject is anchored.
Seedance 2.0 standard prompting formula
Subject + Action + Environment + Camera + Lighting + Style + Quality Constraints
Beyond that, here’s what each element of the formula means:
| Prompt elements | What it should do |
|---|---|
| Subject | Define who or what is in frame |
| Action | Describe the main movement or event |
| Scene | Establish the environment |
| Camera | Clarify shot size, angle, and movement |
| Style | Set the visual treatment |
| Audio | Direct sound, music, or dialogue if needed |
| Constraints | Reinforce quality and consistency goals |
Weak vs. strong: the same idea, two results
Weak prompt:
A cool cinematic ad for a perfume bottle, dramatic, stylish, premium, beautiful lighting. Wide camera, realistic.
That sounds descriptive, but it gives the model very little usable direction. Hence, the result will also be bland and generic.
Strong prompt:
A clear glass perfume bottle sits on a black stone pedestal in a dark studio. Condensation rolls slowly down the glass as a single drop falls onto the surface below. Medium close-up with a slow circular dolly move. Soft side lighting, high contrast reflections, luxury beauty-ad look. Subtle room tone and one sharp glass tap. Stable product shape, clean label detail, natural motion.
The second prompt wins because every part has a job: the subject is clear, the action is simple, the scene is grounded, the camera move is explicit, the style is compact, the audio is intentional.
Here, Clarity beats intensity.
A couple of engine defaults worth keeping in mind while you write a Seedance 2.0 prompt:
-
It has a hard cap of 3,000 characters per prompt. Cut down adjective stacking ("beautiful, stunning, gorgeous light") to one strong word.
-
The model commonly defaults to 720p, 9:16, up to ~15s clips
Seedance 2.0 master template
Here’s a master template which you can directly paste and add all the details in placeholders to formulate your Seedance 2.0 prompt:
[Industry Style], SUBJECT: [Main subject description] ACTION: [Single clear action] CAMERA: [Shot type] + [camera movement] + [lens] ENVIRONMENT: [Location and visual details] LIGHTING: [Physical lighting setup] ATMOSPHERE: [Environmental effects] VISUAL QUALITY: Photorealistic, cinematic composition, premium production design, high detail textures, realistic physics, natural motion, professional color grading, depth of field, subtle reflections CONSTRAINTS: No distortion, no flickering, no extra objects, stable composition, clean motion, consistent identity
Ready-to-use Seedance 2.0 prompts examples (samples + outputs)
These text-only prompts work because they stay focused: one subject, one action, one dominant visual idea. Copy them as-is or swap in your own subject.
1. Cinematic character moment
“A well-groomed hotel concierge in a dark green vintage uniform and matching pillbox hat stands behind a polished wooden reception desk in a luxurious old-world hotel. He looks directly at the camera with a subtle amused smile, lifts a cookie to his mouth, takes a bite, chews naturally, and reacts with a quiet satisfied expression as a few crumbs fall onto the desk. Static medium shot, centered framing, warm amber lighting, rich wood-paneled background, shallow depth of field, cinematic realism, natural hand movement, realistic facial expressions, stable costume details, clean elegant atmosphere.”
2. Product mood test
“A matte silver smartwatch rests on a concrete surface as light passes slowly across the screen. Tight close-up, shallow depth of field, minimalist studio look. Subtle electronic hum.”
3. Abstract/atmospheric short
“A paper lantern floats through a dark room filled with dust and soft amber light. The camera follows slowly from behind. Dreamlike, quiet, intimate.”
4. Luxury product ad
“A clear glass perfume bottle sits on a black stone pedestal in a dark studio. Condensation rolls slowly down the glass as a single drop falls onto the surface below. Medium close-up with a slow circular dolly move. Soft side lighting, high contrast reflections, luxury beauty-ad look. Subtle room tone and one sharp glass tap. Stable product shape, clean label detail, natural motion.”
5. Nature and landscape (aerial)
“A lone red kayak cuts across a glassy turquoise lake at sunrise, leaving a soft wake behind it. Wide aerial drone shot slowly pulling back and rising to reveal pine forest and snow-capped peaks. Golden morning light, crisp natural color, subtle mist on the water. Quiet ambient wind and distant birdsong. Stable horizon, smooth motion, photorealistic detail.”
6. Food and beverage close-up
“A barista pours steamed milk into a dark espresso, forming a slow rosetta pattern on the crema. Tight overhead close-up with a gentle push-in. Warm cafe lighting, shallow depth of field, glossy reflections on the cup rim. Soft pouring sound and quiet background chatter. Natural liquid motion, stable cup, rich appetizing color.”
7. Fashion and portrait
“A model in a flowing crimson gown walks slowly toward the camera down an empty concrete corridor, fabric trailing in the air behind her. Medium tracking shot following her stride, eye-level framing. Cool directional side light, high-fashion editorial look, muted background tones. Faint echoing footsteps. Consistent face and wardrobe, natural walk cycle, confident expression.”
8. Sports and action
“A skateboarder launches off a concrete ledge and lands a clean kickflip in an urban skatepark. Low-angle tracking shot rising with the jump, fast shutter feel. Bright midday sun, hard shadows, gritty street palette. Sharp board clack on landing and rolling wheels. Stable rider proportions, crisp motion, dynamic energy.”
9. Animated and stylized scene
“A young girl in a yellow raincoat splashes through puddles on a quiet street while paper boats float beside her. Side-scrolling tracking shot keeping pace with her. Soft hand-drawn 2D animation style, warm pastel palette, gentle rain texture. Light rainfall and playful splashes. Consistent character design, smooth frame-to-frame motion, cozy storybook mood.”
10. Automotive and product reveal
“A matte black sports car sits in an empty underground parking garage as overhead lights flick on in sequence down the length of the car. Slow low-angle arc shot circling from the front wheel to the headlight. Cool blue practical lighting, wet concrete floor with sharp reflections, premium commercial look. Low engine hum and a soft electrical click as each light turns on. Stable car proportions, clean paint surface, natural reflection motion.”
Seedance 2.0 best prompts examples: Reference-driven and multi-shot videos
When references and sequences come into play, structure matters even more. These are the prompts to reach for when motion, timing, or storytelling are the point.
Reference-driven prompt
When a reference frame is involved, your prompt should get shorter, not longer, because it already carries the details of the beginning scene. Specify the style capsule, the subject identity, the camera intent, and any pace anchors; leave out the exact motion path.
Prompt: “Use the reference @image1 for the slow push-in and hand movement. Keep the ceramic mug shape and handle proportion stable. Replace the original setting with a warm kitchen counter in soft morning light. Neutral palette, clean reflections, natural steam. Hold the final frame slightly.”
Reference input:
 |
Output: |
Multi-shot sequence prompt (label each shot)
Don't write one long paragraph and hope the model finds the cuts. Label the shots, and give each one a main action and a main camera instruction.
Prompts: Shot 1: Extreme close-up of a black sneaker hitting wet pavement, droplets splashing outward. Low angle, fast shutter feel. Shot 2: Medium tracking shot as the runner moves through a neon alley, breath visible in the cold air. Shot 3: Tight push-in on the shoe logo as he stops under a red street light. Tense urban mood, cold blue palette, distant traffic and wet footsteps.
Advanced multimodal prompt (text + many images)
With the @ system you can choreograph a subject across multiple image worlds in one prompt:
Prompt: “Use @frame1 as the opening composition. A lone futuristic warrior stands on a vast crimson alien desert beneath towering rock formations and swirling red storm clouds, holding a glowing energy sword. Camera performs a slow cinematic dolly forward from behind the character, volumetric dust drifting through the scene, epic scale, dramatic atmosphere, cinematic science-fiction film quality. Transition naturally into @frame2. The warrior suddenly crashes into the desert surface at extreme speed, generating a massive shockwave. Dust erupts outward, sparks scatter through the air, rocks and debris fly toward the camera. Aggressive push-in camera movement, realistic physics simulation, intense cinematic energy. Continue into @frame3. The warrior accelerates into a full sprint across the battlefield. Low-angle tracking shot from behind, dust trails streaming from his feet, glowing energy sword creating subtle light streaks. Large alien cliffs rush past with strong environmental parallax, increasing momentum and speed. Transition into @frame4. The camera swings from behind to a dynamic side-tracking angle as the warrior charges forward. Flying debris, sparks, dust storms, kinetic movement, cinematic camera shake, high-speed pursuit energy, blockbuster action cinematography. Move into @frame5. The warrior lowers his stance as immense energy begins building in the distance. The camera performs a slow orbital movement around him. Dust storms intensify, rocks vibrate and lift slightly from the ground, atmospheric tension rises before the climax. Continue into @frame6. The warrior launches into the air between towering alien rock formations. Camera tracks smoothly alongside him. The glowing energy sword leaves bright light trails through the atmosphere. Dust and debris swirl beneath him, dramatic perspective, large-scale science-fiction spectacle. Finish with @frame7. A colossal explosion engulfs the landscape. Massive fireball expansion, shockwaves ripple through the desert, gigantic rock fragments blast outward, volumetric fire and smoke simulations. Camera pulls back slightly to reveal the scale of destruction. Epic blockbuster finale, overwhelming sense of power and scale. Ultra-realistic science-fiction film, premium VFX, cinematic lighting, volumetric atmosphere, realistic debris simulation, physically accurate dust and particles, dramatic environmental destruction, high detail textures, filmic contrast, orange-red color palette, dynamic motion blur, depth of field, smooth shot transitions between reference frames, AAA movie-quality cinematography, consistent character design, consistent energy sword, seamless action progression, cinematic pacing, professional visual effects.”
What prompt types power Seedance 2.0 AI video generation?
At a practical level, Seedance 2.0 is a multimodal video model. That means it can work from far more than text. In a single prompt window, you can combine written prompts with images, video references, and audio references, up to:
-
9 image references (up to 6000 × 3000 px)
-
3 video references (≤15 sec total · 720p · 24fps)
-
3 audio references (≤15 sec total)
-
12 files total across all types
The mental model: text is spatial, video is temporal
If you remember one thing, make it this: text is best for spatial decisions, reference video is best for temporal decisions.
Spatial decisions are about what the world looks like: subject, wardrobe, product appearance, location, lighting, mood, color, and style. Text handles these well.
Temporal decisions concern what happens over time: timing, rhythm, gesture cadence, camera motion, beat sync, and the exact shape of movement.
This is where text wobbles. You can write "slow push-in," but that's still being interpreted. A reference clip doesn't describe the move; it contains it.
Choose your workflow before you write
Text-to-video: You're still exploring an idea, testing a mood, or chasing loose visual direction.
Prompt: “Hand-drawn comic style, three people sitting together eating the fried chicken from @image1, the atmosphere is friendly and joyful, then the scene gradually blurs, and the text "Joy is in Seedance" appears in the center of the screen.”
Reference image:
 |
Output video: |
Image-to-video: You already know how the scene should look and want to preserve a starting image (character, product, composition).
Prompt: “Extract the camera from @Image1, @Image2, and @Image3, replace the background with white. The camera sits on a white table, the lens focuses on the camera in close-up, then slowly rotates around the camera as the main subject, clearly showcasing the front, side, and back.”
Reference input:
 |
Output: |
Reference-to-video: Timing, choreography, gesture rhythm, or camera movement matters most. A clean reference clip does more for motion than fifty extra words.
Prompt: “Reference the running form of the horse from Video 1, generate a golden horse galloping on a grassland, then freeze-frame its magnificent running pose, transforming into a horse-shaped gold pendant.”
| Reference input: | Output: |
Action prompts vs. feel prompts
Seedance 2.0 also responds to two distinct prompt styles:
Action prompt: break movement into clear, sequential beats using an arrow format, like a shot list.
Example: woman walks into a dimly lit bar › she pauses and looks around slowly › moves toward the window › pulls back the curtain › golden light floods across her face.
Feel prompts: skip choreography and describe the emotional tone instead.
Avoid (over-specified)
A man sits down, taps the desk three times, exhales, and then opens his laptop.
Try instead (feel-based)
A tense, restless energy — the kind of quiet that comes before a big decision.
Other capabilities
-
Frame-to-frame interpolation (give it a start frame and an end frame)
-
Reference mode for style/motion/lip-sync,
-
Video Edit for in-painting or layer modification
-
Extend to lengthen an existing clip while keeping temporal consistency
The @ mention system: where real control starts
When you upload assets, don't just mention them. Assign each one a role with an @. This is the difference between the model guessing and the model knowing.
@image1 Reference character (use for appearance only)
@image2 Background reference
Skip the extensive prompting: use Seedance 2.0 in invideo and AgentOne
If all of this sounds like a lot of dialing in, you don't have to do it manually. Inside invideo, you can run Seedance 2.0 in a complete workflow (generation, iteration, editing, and export in one place), and you can hand the prompt-crafting itself to an AgentOne AI video agent.
How to set it up:
Sign up on invideo (paid users get free, unlimited access for 7 days), then open Agents & Models.
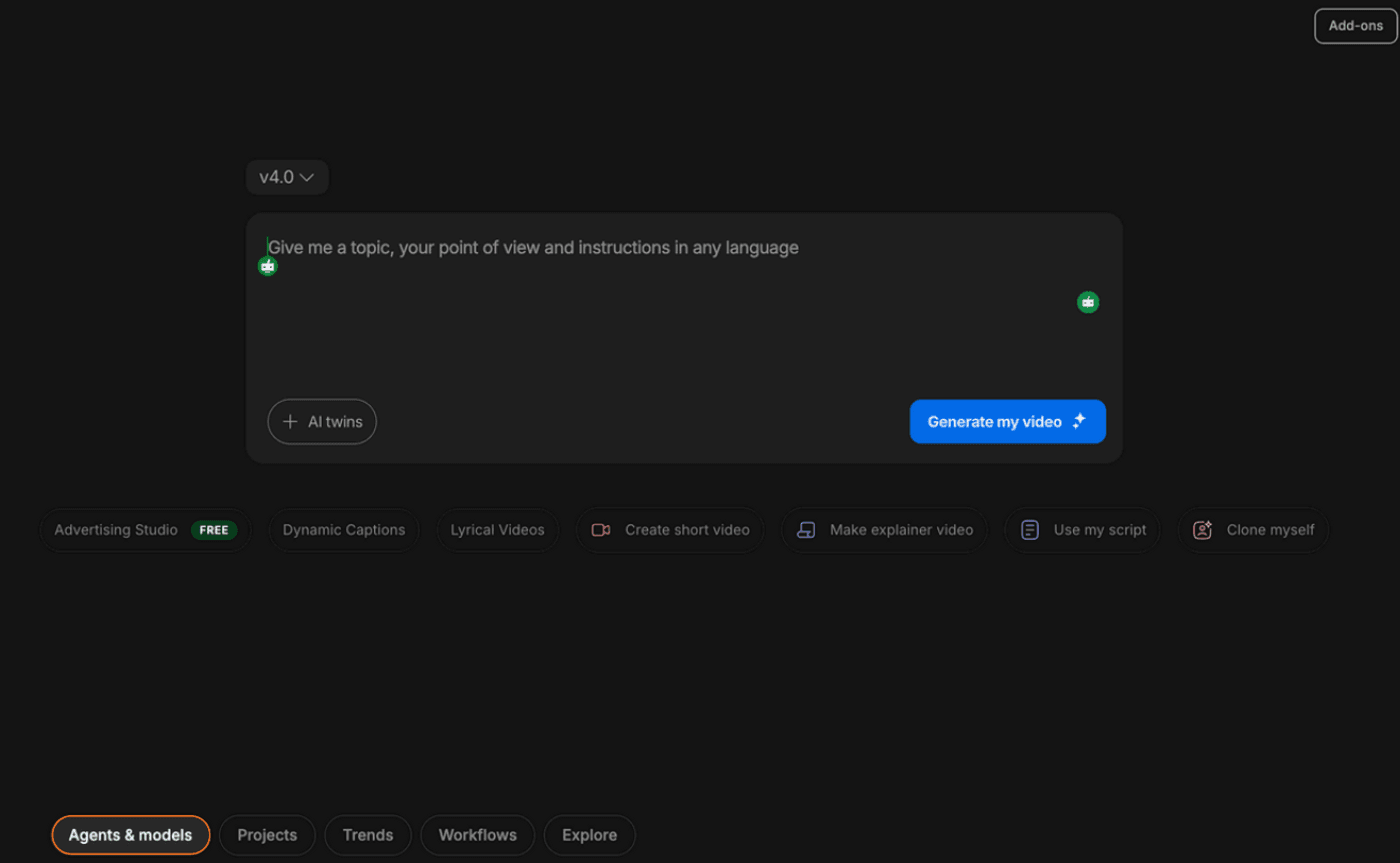
Go to Agents → New Agent.
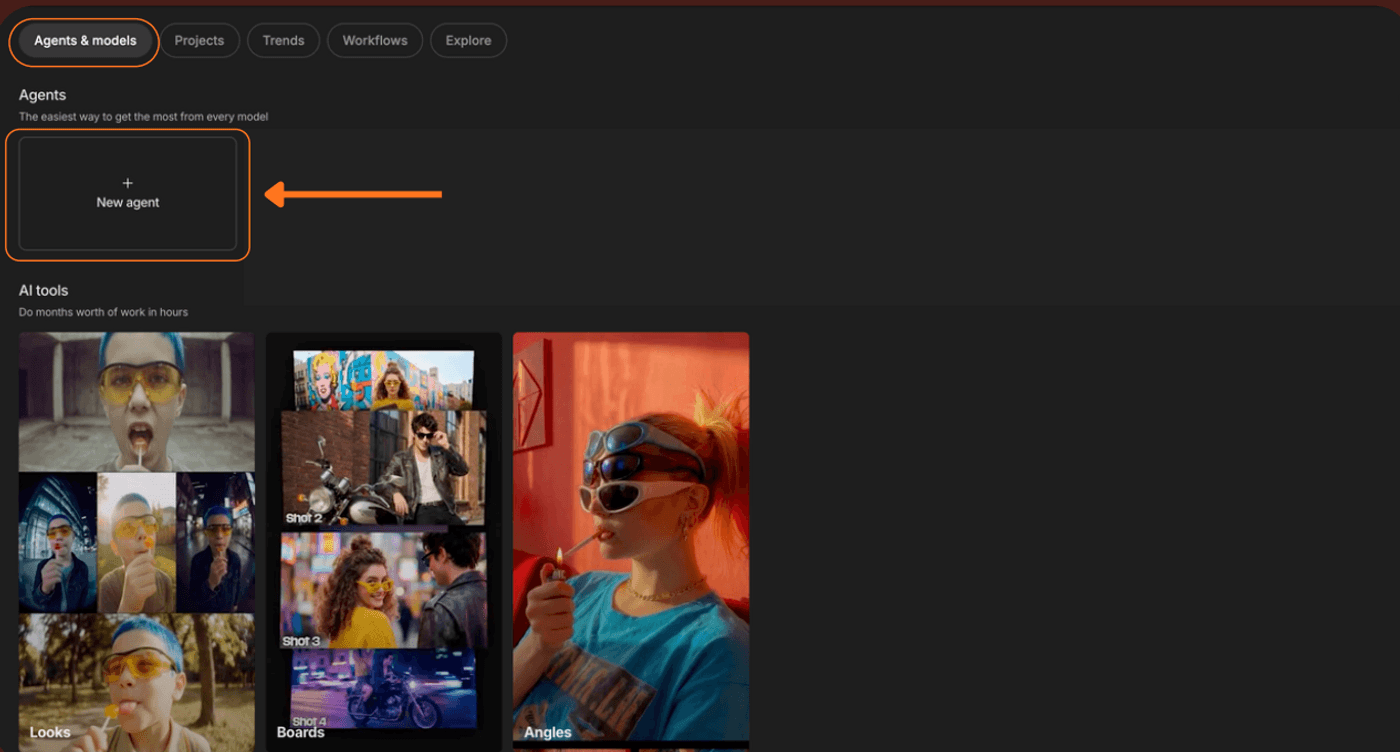
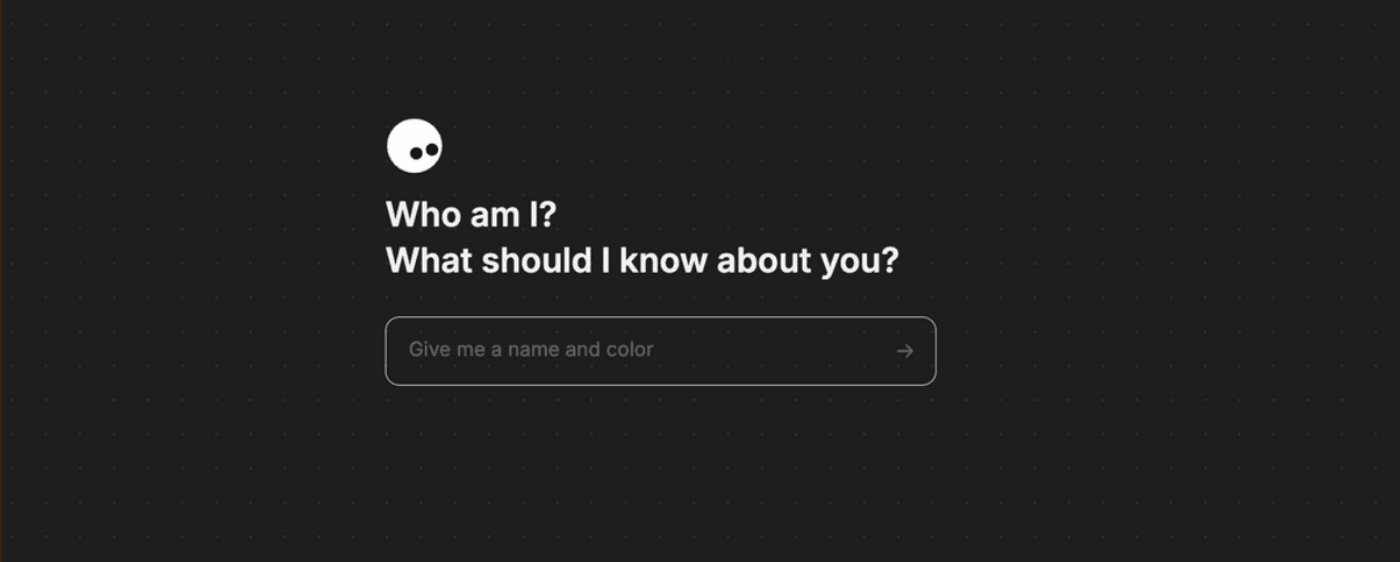
Name your agent. This becomes your AI video agent for the project, so you chat with it and describe everything you want to do.
-
Prime it once. Paste a short operational instruction as the first message so the agent defaults to Seedance 2.0 and your preferred settings (model, resolution, aspect ratio, max duration) every time.
IMPORTANT: If you use reference images, video, or audio, make sure you actually have the right to use them: get consent from people in frame, avoid unlicensed music and visible third-party logos, and remember that "found online" is not the same as licensed.
Conclusion: Create videos with Seedance 2.0 like you’re briefing a creative team member!
The best Seedance 2.0 prompts aren't the longest ones; they're the clearest.
Once each input has a clear role, the model stops feeling unpredictable and starts feeling directable.
That's the real shift: better prompting isn't about sounding smarter, it's about giving the model better control signals. Lead with your subject, give every input a job, use concrete camera language, write sound into the prompt, phrase everything positively, and iterate from short tests.
Do that or let AgentOne do it for you, and Seedance 2.0 AI video generation becomes a repeatable system instead of a lucky render.
FAQs
-
1.
What is Seedance 2.0?
Seedance 2.0 is a multimodal AI video model that works from text, images, video references, and audio together. Its main advantage is giving creators more control over consistency, motion, camera behavior, and sound than a text-only workflow.
-
2.
How do you use Seedance 2.0?
Choose the right workflow first, then prompt with structure. Use text to define subject, action, scene, camera, style, and audio. Add image references when identity or appearance must stay stable, and video references when timing or motion matters. Then iterate based on what actually failed in the output.
-
3.
Is Seedance 2.0 better with text prompts or reference videos?
Neither is universally better; they solve different problems. Text is better for visual direction, mood, setting, and style. The reference video is better for timing, motion, pacing, gesture rhythm, and camera curves. The strongest results usually combine both with clear roles.
-
4.
Can Seedance 2.0 generate audio with prompts?
Yes. Seedance 2.0 can generate ambience, sound effects, a musical feel, and some dialogue. Audio direction works best when you describe the sound clearly in your prompt instead of leaving it implied.
-
5.
What is the best prompt structure for Seedance 2.0 AI video generation?
The standard Seedance 2.0 prompting formula/structure is "[Format/Shot Structure] + [Subject] + [Action] + [Camera Movement] + [Environment/Lighting] + [Style/Mood]". This order keeps the prompt readable while ensuring every important part of the generation is covered.
-
6.
How can I improve my prompts for consistency in Seedance 2.0 AI video outputs?
Avoid overloading the prompt with adjectives or multiple actions in one shot, and debug the real issue instead of rewriting everything at once. Additionally, use fewer but better references, keep shots simple, and let images lock identity, video lock motion, and text lock style.