Quick Rundown
-
Google announced Gemini Omni at I/O 2026 on May 19, 2026, with Gemini Omni Flash as the first model in the family.
-
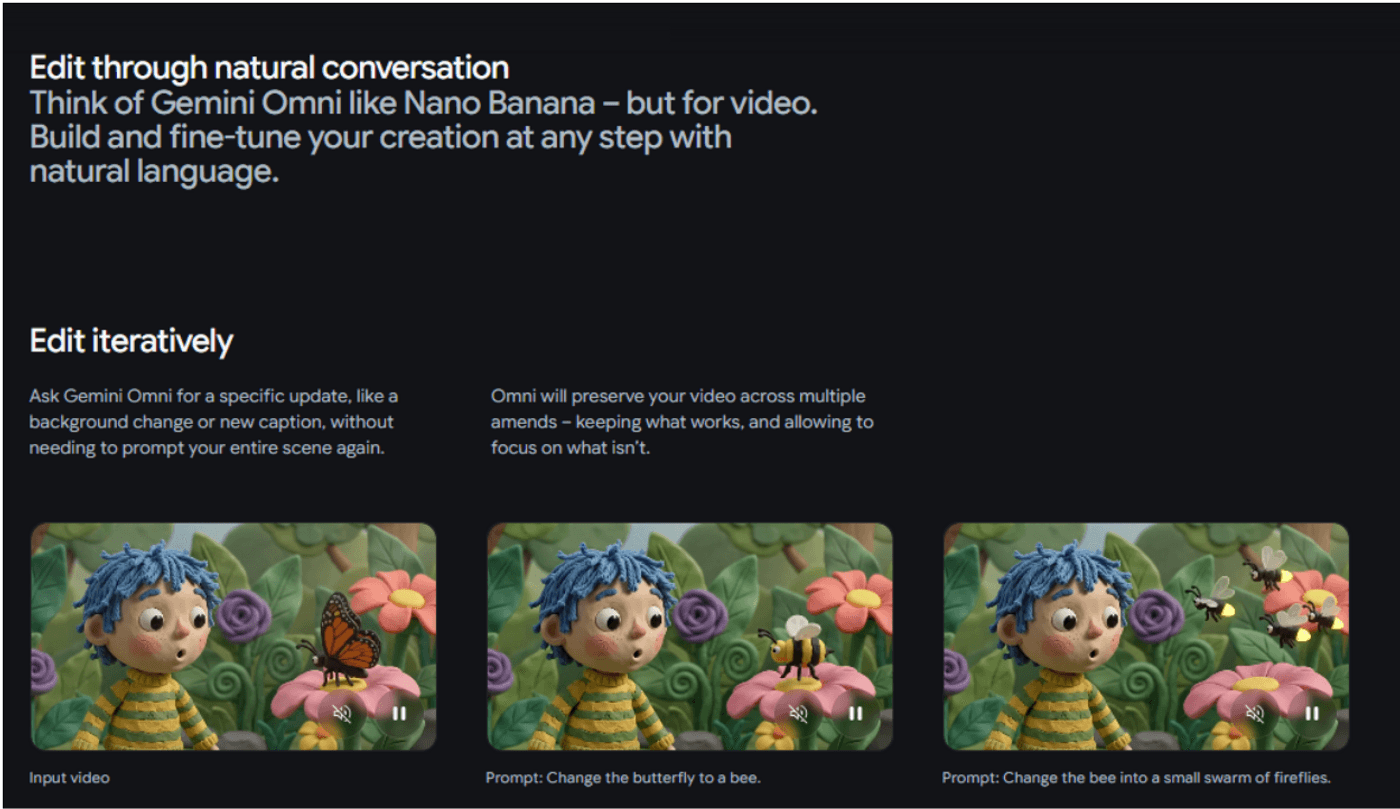
It's Nano Banana for video. You edit through conversation, and every detail you didn't ask to change stays exactly where it was.
-
It accepts text, images, video clips, and voice as inputs, and generates video up to ten seconds long with synchronized audio.
-
The prompt philosophy shifts from specification to direction, where you describe what matters and the model handles the craft layer.
-
Voice-editing on existing footage was deliberately held back over deepfake risk, so you can put your voice into a generated video but not rewrite someone else's.
-
Reach for Omni Flash when you need multi-turn editing, knowledge-grounded explainers, concept exploration, or avatar content. Skip it for hero shots, long-form, or voice-rewriting.
Whenever a new video model drops, the default move is to line it up against the leader. Same prompt, multiple rounds and you pick a winner.
That reflex is sound. It's how creators have been deciding which model to pay for all year. Seedance 2.0 leads on cinematic quality. Kling 3.0 owns motion fidelity.
On that benchmark, Google Omni will probably lose to Seedance.
That benchmark isn't broken because Omni would lose it. It's broken because the two models aren't trying to answer the same question.
With Seedance 2.0: A perfect prompt gets you a perfect video. But you're not in control of the tiny details. The model decides what they look like.
With Omni: You are always in control. You make edits through conversation until every little detail is the one you intended.
Google's own framing makes this explicit. Omni is to video what Nano Banana was to images.
Iterative editing where the parts you didn't touch stay untouched. Fifty billion images later, that's what people use Nano Banana for.
Omni is that, in motion.
What is Gemini Omni Flash?
Google announced Gemini Omni at I/O 2026 on May 19.
The first model in the family is Gemini Omni Flash, available in the Gemini app, Google Flow, YouTube Shorts, and the YouTube Create App.
And it lives up to the name. It can take any reference inputs in any format:
-
Text
-
Images
-
Video clips
-
Audio
Output: video up to ten seconds with synchronized audio.
The technical claim Google is making matters here.
Omni isn't a video model and a reasoning model stitched together at inference time.
It's one model that reasons across all four input modalities and generates video grounded in Gemini's world knowledge: physics, history, science, cultural context.
Koray Kavukcuoglu, CTO of Google DeepMind and Chief AI Architect at Google, frames it as the model "where Gemini's ability to reason meets the ability to create."
Is Gemini Omni Flash an upgrade on Google Veo 3.1?
The short answer is, No.
Veo 3.1 now sits as a standalone video model on the DeepMind site. Gemini Omni Flash however, now sits under the core Gemini family alongside Nano Banana and Gemini Audio.
It’s available on the Gemini app and Flow for Google AI Plus, Pro, and Ultra subscribers.
It’s free on YouTube Shorts and the YouTube Create App.
API for developers and enterprise rolls out in the coming weeks.
Omni Pro is announced but unreleased. Google says it ships "when we feel like we're at a point where we have a step change above Flash." For now, Flash is the only Omni model that exists.
Gemini Omni Flash: The big conversational claim
The Deepmind prompt guide says this:
"With Veo 3.1, you need to share precise instructions to get the best results. But with Gemini Omni, you don't have to be as prescriptive with your prompt."
For the last year, getting good output from Veo 3.1 (or Seedance 2.0, or Kling 3.0) meant learning the model's prompt language.
-
Camera move keywords
-
Lighting modifiers
-
Subject-action-camera-style-constraints stacks
-
Lens specs, depth-of-field calls, color grade modifiers
The skill that mattered was Prompt engineering: describing the shot so precisely the model couldn't ambiguate it.
Omni inverts that contract. You describe what matters to your vision. The model's reasoning handles the craft layer.
The shift isn't to just "describe less."
It's to describe what you can't delegate, delegate what you can.
Your creative direction stays specific. The technical specification is what the model can handle.
In practice, this is what it looks like:
Veo-style prompt:
"A woman in her late 20s with auburn hair, wearing a cream wool coat, walks slowly from left to right through an autumnal forest. Wide shot, 35mm lens, shallow depth of field, golden hour side lighting, warm cinematic color grade. Slow dolly tracking shot, camera at chest height. Leaves falling from camera-right, occasional lens flare. She doesn't smile, doesn't look at camera. Mood: melancholy, contemplative. 5 seconds."
Gemini Omni-style prompt:
"A woman in her late 20s with auburn hair, in a cream wool coat, walking through an autumn forest. She's thinking about something she can't quite let go of. Shoot it like a Sofia Coppola film."
What dropped: lens choice, depth of field, lighting direction, color grade, dolly speed, camera height, leaf physics, duration.
Those are things Omni's reasoning fills in because it knows what a Sofia Coppola film looks like, what late-afternoon forest light does, and what "thinking about something she can't quite let go of" means for posture and pacing.
The Veo 3.1 prompt is a shot list.
The Omni prompt is direction.
That posture shift is what makes the rest of Omni's capabilities usable. Now look at what they actually do.
What features does Gemini Omni Flash offer that other AI video models can't?
1. Multi-turn editing, the load-bearing one
This is the headline.
Talk to a video the way you'd talk to a human editor. Every instruction builds on the last.
Characters stay consistent
Physics holds
The scene remembers what came before
The violinist demo that google posted is the workflow proof.

Three consecutive edits, no re-prompting from scratch.
Seedance 2.0 lets you specify the perfect shot from the perfect prompt. Omni lets you refine your first gen into one.
2. World-knowledge grounding
This is the Gemini reasoning in action.
The cleanest demo: a one-line prompt that reads "claymation explainer of protein folding."
Omni rendered alpha helices and beta sheets with a synced voiceover.
The model didn't just generate a stop-motion video. It knew what protein folding looks like.
The 26-item alphabet demo is the same point in a different costume:
Omni picked unusual items for each letter, rendered them at roughly nine frames per item, synced lower thirds. Reasoning rendered as video.
3. Reference-anything inputs
Combine images, video clips, audio, and text in one prompt.
Pose from a video, style from an image, motion from another video, music from an audio track, all into a single coherent output.
Audio reference is voice-only at launch; other audio types are still yet to come. Seedance 2.0 is also multimodal, it accepts 9 images, 3 video clips, 3 audio tracks.
What Omni adds isn't more inputs. It's reasoning across them.
4. Avatars

Gemini Omni Flash stores an AI avatar that is a digital version of you that looks and sounds like you.
Generate yourself winning an award, walking on the moon, removed from the background of your own vacation footage.
Barth-Maron called it "personalized memes."
What Google Omni Flash deliberately left out?
Not dropping voice-editing is the most interesting gap.
You can put your voice into a generated video via an avatar. You cannot upload someone else's clip and rewrite what they're saying.
Google's launch post wording on this is unusually candid: "we are still working to test this and better understand how we can bring this capability to users responsibly."
Plain English: the deepfake-audio risk was too high to ship without further guardrails. It is an honest call.
The ten-second cap is a deployment decision, not a model limit.
Per Brichtova, Google wants wider access while the computer is constrained, and most consumers don't want longer clips yet.
The workflow implication is that you'll be stitching clips together, not generating long-form videos. Veo 3.1's consumer cap is similar, so this isn't a regression.
When to use Gemini Omni Flash, when to reach for something else
Every model in your stack should be earning its slot by doing something specific better than the alternative. Apply that test to Omni.
What Omni is genuinely better at than anything currently shipping:
-
Multi-turn iteration on a clip you already have or just generated. The violinist loop is the proof. Veo can't do this. Seedance can't do this. Kling can't do this
-
Knowledge-grounded explainers, anything where the model needs to know what something is before it can render it. The protein folding demo, the alphabet rapid-fire
-
Concept exploration through conversation when you don't yet know what the scene should look like. Omni's looser prompting posture lets you iterate toward it instead of front-loading every decision
-
Personal-likeness content through avatars, a content category that previously required filming yourself
What Omni is probably not the right tool for, yet:
-
Hero shots where raw generation quality is the only thing that matters. Omni's cinematic quality may lag Seedance 2.0 and Kling 3.0. If you're rendering a single clip for a finished piece and there's no edit pass after, the other models might give you a cleaner first generation
-
Long-form. The ten-second cap forces stitching workflows
-
Voice-rewriting on existing footage. Doesn't ship
The honest test: if your bottleneck is the first generation, the cinematic-quality models still win. If your bottleneck is the fifth generation, the one where you're refining what you've already got, then Omni is the model that didn't exist last month.
So, Is Gemini Omni Flash “better”?
The answer is not a definite ‘yes’ or ‘no’.
The better question to ask is whether the workflow it enables (talking to your video, refining instead of restarting, trusting the model to handle the craft layer while you direct the intent) is one you want.
The only way to know is to open it. The violin is yours.
FAQs
-
1.
What is Google’s Gemini Omni Flash?
Gemini Omni is Google's new family of multimodal generative AI models, announced at I/O 2026. The first model out is Gemini Omni Flash. It takes text, images, video clips, and audio as inputs and generates video as output, with conversational multi-turn editing as its headline capability. Google positions it as "Nano Banana for video."
-
2.
Is Gemini Omni Flash free?
Partially. Gemini Omni is free on YouTube Shorts and the YouTube Create App. In the Gemini app and Google Flow, it requires a Google AI Plus, Pro, or Ultra subscription. API access for developers and enterprise rolls out in the weeks after launch.
-
3.
Does Gemini Omni Flash replace Veo 3.1?
Only in the Gemini app. That's the precise wording from Google's own help page. Veo 3.1 remains live on Vertex AI, the Gemini API, and Google AI Studio. The DeepMind site now classifies Veo as a "Specialized model" while Omni sits under the core Gemini family alongside Nano Banana and Gemini Audio.
-
4.
How long can Gemini Omni Flash videos be?
Up to ten seconds with synchronized audio. Per Nicole Brichtova, DeepMind's director of product management, the cap is a deployment decision rather than a model limit. Longer durations are on the roadmap but unscheduled.
-
5.
Can Gemini Omni edit the voice in a video?
No. You can put your own voice into a generated video through the avatar feature, but you cannot upload an existing clip and rewrite what someone is saying. Google held this back deliberately, citing the need to test responsibly before shipping voice-editing capabilities.
-
6.
How is Gemini Omni Flash different from Veo 3.1?
Two things matter. First, Omni is conversational and multi-turn: you can refine a clip three or four times in a row and the model holds character and scene consistency across edits. Veo can't do that. Second, the prompt philosophy is different. Veo rewards precise, specification-heavy prompts (lens, lighting, color grade). Omni's reasoning fills in the craft layer when you describe intent rather than specifying every detail.