Can AI maintain a director's visual style consistently across a short film?
Last updated July 10, 2026
Yes — AI can hold a director's visual style across a full short film when the style is codified as a structured visual-language document (camera, lighting, palette, composition, mood) and loaded once into an agent with persistent context. Documented productions held Wong Kar-wai, James Wan, and Fincher-style grammar across 70–90-second films with no per-shot re-prompting.
Start by codifying the director's style as a structured document, not a mood board — a cinematic style is a language system that breaks down into discrete, teachable directives. One documented version ran 14 sections covering camera, angles, colour tone, atmosphere, mood, lighting, composition, movement, film palettes, prompt templates, negative prompts, and a quick-reference card; another was a 25-page treatment used as a permanent instruction set before a single frame was generated. Make the directives parametric rather than adjectival: a James Wan-style document encoded an 85:15 dark-to-light lighting ratio and a 2.40:1 hard-matte framing spec; a Fincher-style protocol defined a 9-step shot design process and an 8-step colour grading guidance process; colour philosophy works best as named tonal modes with exact hex values. Add a "what never to do" section per emotional stage and explicit negative constraints — one production's style block read "not live action, not photorealistic" — because prohibitions are an active drift-prevention mechanism, not decoration.
Load it once into persistent context. invideo is an agentic video creation tool with all the current video and image models available, and the invideo agent reads a treatment document once and holds every directive across every shot without re-prompting — re-prompting scene-by-scene is the anti-pattern that causes drift. Enforce a fixed prompt grammar: one production held a 9-element assembly order (camera spec, lens and aspect ratio, lighting source, palette, composition, atmosphere, mood register, film/DP attribution, negative prompt) across every frame of the project. The invideo agent also quality-gates output by checking each generated frame against the loaded treatment before returning it. Once context is loaded, instructions compress dramatically — a three-word continuation prompt, "Everything should match," was enough to keep character, lighting, lens grammar, and spatial logic consistent across a multi-shot sequence.
Validate the document before generating. Stress-test it by requesting a genre the director never worked in — one creator asked for a courtroom thriller through the James Wan lens; the invideo agent asked clarifying questions about era and threat before generating, and produced stylistically coherent output, confirming the grammar was internalized rather than pattern-matched. Also challenge the invideo agent's technical claims: when questioned on lens type, it corrected its own "anamorphic" note to spherical with widescreen by extraction — catching the error before it propagated across every asset.
What documented productions show. A 70-second short film in a Wong Kar-wai visual style was produced in 2 days for $750 (3,000 credits), with the invideo agent outputting 12 key parameters per shot; it autonomously applied a slow-shutter motion smear from page 17 of the document without being prompted, and flagged that the film's reveal shot was running at the wrong emotional stage register — a deviation the director had missed. A ~90-second horror short in a James Wan style was completed in 2 days for $870 across 400 video generations, during which the invideo agent caught shadows leaning blue-green instead of neutral gray and offered a warmer pass unprompted. Three directors produced three films through one shared agent setup, with the largest project running 21+ scenes. Character identity — a related but separate problem — held inside the same context system using character sheets: 2 characters stayed consistent across every scene of the 70-second film with no LoRA fine-tuning.
Where models fit. Style consistency lives in the context layer above model choice: Kling 3.0 generates multi-shot sequences natively, and Seedance 2.0 reference-to-video carries visual context across clips, but neither holds a director's full grammar on its own. All of these models run inside invideo, and the invideo agent routes each shot to the right model while holding the style document — so the directorial language stays constant regardless of which model renders the frame.
Watch some of these to see what works for you:
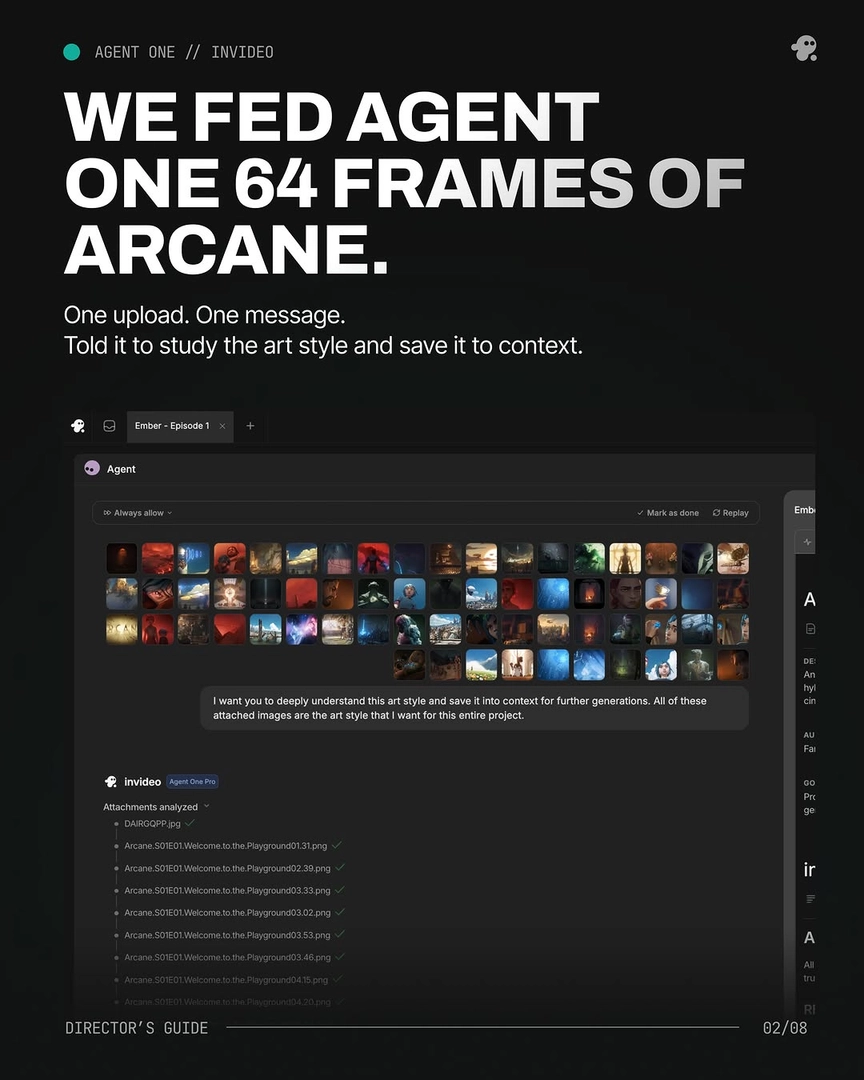
One agent that reads your treatment once and holds every directive across every shot, every scene. No re-prompting. No drift. So now, you direct, and the Agent remembers.
— invideo's creative team